
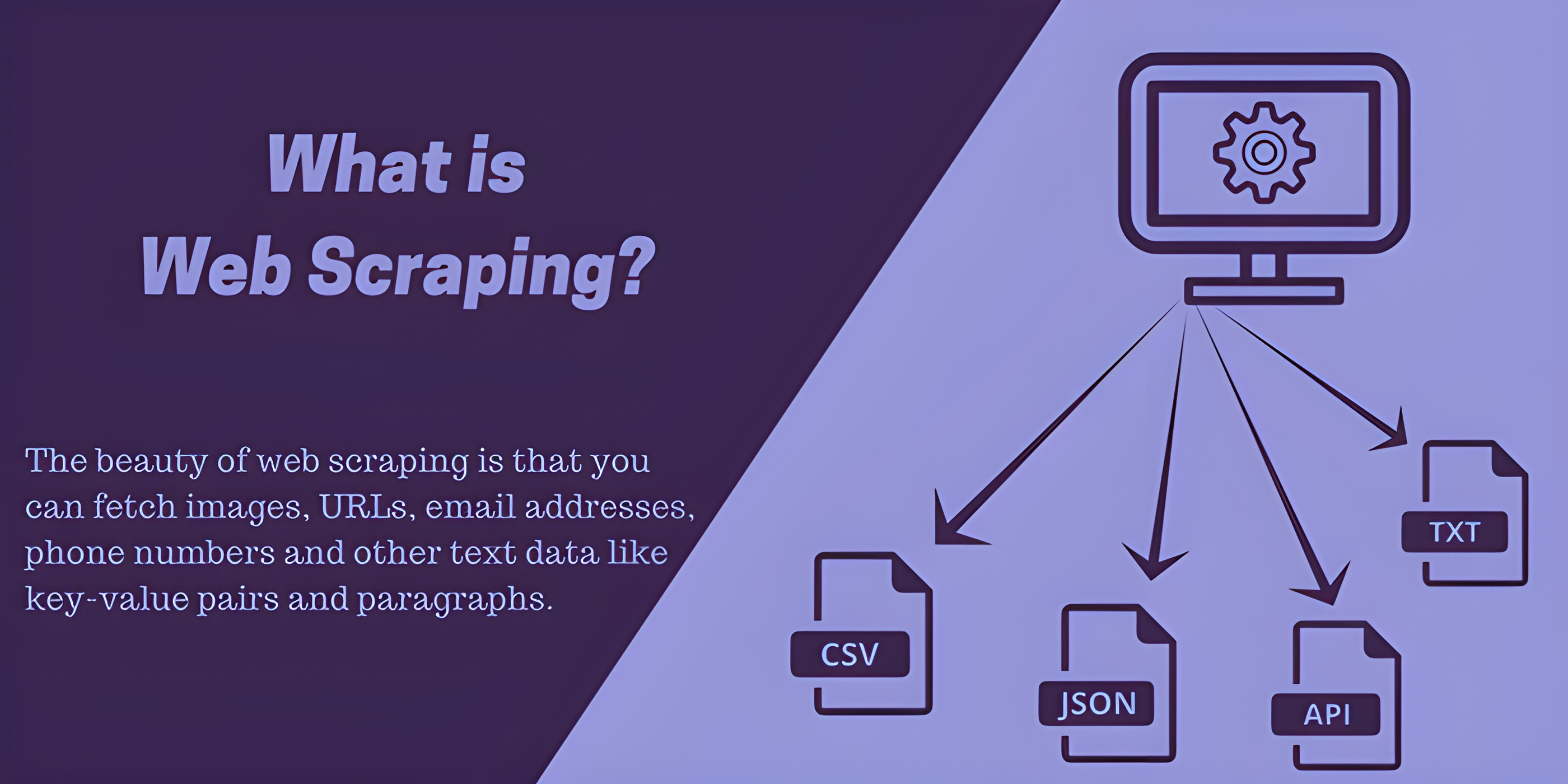
===
In today’s data-driven world, web scraping has become an essential tool for extracting valuable information from websites. Whether it’s gathering pricing data, monitoring competitors, or conducting market research, having an efficient and scalable event-driven web scraping system can make all the difference. In this article, we will explore the key elements of building such a system and how it can revolutionize your data collection process.
Creating an Event-Driven Web Scraping System: Efficient and Scalable!
When it comes to web scraping, efficiency and scalability are crucial factors. An event-driven system allows you to scrape multiple websites simultaneously without overwhelming your resources. By leveraging event-based programming, you can utilize asynchronous operations to handle multiple requests concurrently. This means that while waiting for a response from one website, your system can continue processing requests from others, resulting in a faster and more efficient scraping process.
To achieve scalability, consider implementing a distributed architecture. By distributing your scraping tasks across multiple machines or nodes, you can easily handle large volumes of data without overburdening a single system. This allows you to scale up or down based on your needs, ensuring that your system remains responsive even during peak traffic periods. Additionally, you can use load balancing techniques to evenly distribute the workload among your scraping nodes, further enhancing the scalability of your system.
Another important aspect to consider when building an efficient and scalable web scraping system is employing smart resource management. By optimizing resource usage, such as memory allocation and thread management, you can ensure that your system operates smoothly even when dealing with large datasets. Implementing caching mechanisms and intelligent scheduling algorithms can help minimize the number of unnecessary requests and reduce the overall load on your system.
Mastering the Art of Web Scraping with an Efficient, Scalable System!
Building an efficient and scalable web scraping system requires mastering a few key techniques. One such technique is implementing intelligent retry mechanisms. As websites often experience temporary downtime or request limits, it is important to handle these situations gracefully. By automatically retrying failed requests after a certain interval or implementing a backoff strategy, you can ensure a higher success rate and minimize the impact of errors on your scraping process.
Additionally, using intelligent data extraction techniques can greatly enhance the efficiency of your system. Instead of scraping entire web pages, focus on extracting only the required data elements. This can be achieved using XPath queries or CSS selectors to pinpoint the desired information without unnecessary overhead. By doing so, you can reduce the amount of data transferred and processed, resulting in faster scraping times and improved system performance.
Lastly, automating the monitoring and error handling process is essential for maintaining a robust web scraping system. Implementing a logging mechanism to keep track of successful and failed requests, as well as any issues encountered during the scraping process, can help you identify and resolve problems quickly. By setting up alerts or notifications, you can be alerted in real-time if any critical errors occur, allowing you to take immediate action and ensure the smooth operation of your system.
===
Building an efficient and scalable event-driven web scraping system is no small feat, but the benefits it brings to your data collection process are invaluable. By following the techniques and considerations outlined in this article, you can streamline your scraping operations, increase efficiency, and handle large volumes of data with ease. Remember to always abide by the website’s terms of service and respect their usage limits to maintain a positive and ethical scraping practice. Happy scraping!
Add Comment